A Choice for ''Meaningful Progress''
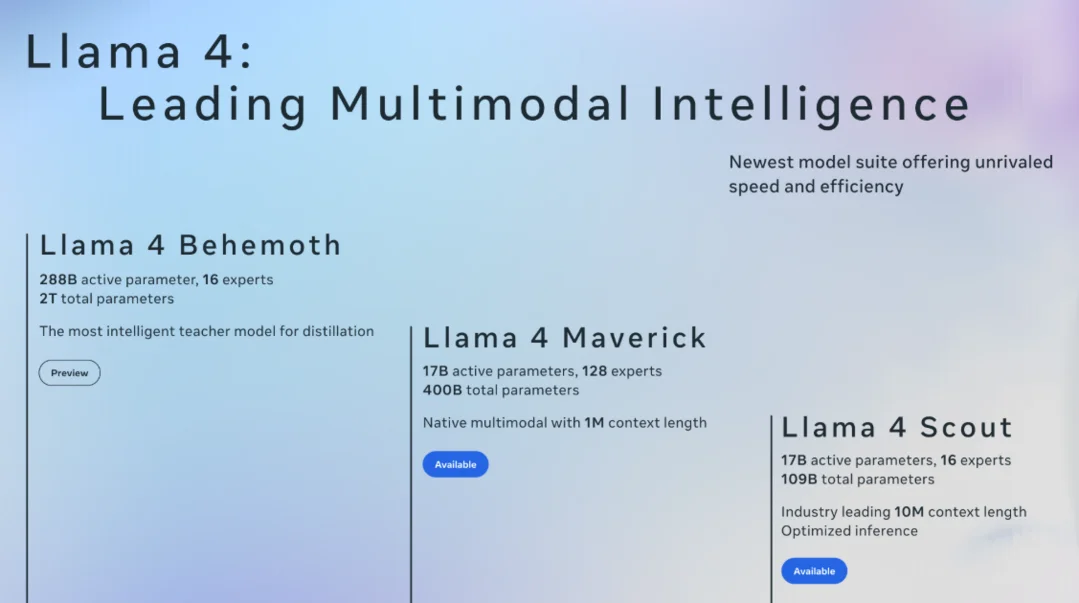
Meta's next-generation large language model Llama 4 "Behemoth" has been delayed to fall 2025 or later, following an earlier delay from the April LlamaCon event to June. The delay stems from internal performance concerns and reevaluation of AI industry expansion strategy. Behemoth specifications: Mixture-of-Experts (MoE) architecture; approximately 2 trillion parameters; context window up to 10 million tokens. Internal assessment revealed it failed to demonstrate "overwhelming quality difference" vs. existing models (Llama 3) — Computerworld reported internal feedback that Behemoth increased resource inefficiency and operational difficulty without proportional capability gains. The MoE architecture context: MoE activates only a subset of parameters for each forward pass, theoretically enabling massive parameter counts with manageable compute; but training stability and routing efficiency remain challenges, and Behemoth appears to have encountered the fundamental tension between scale and quality that afflicts many frontier models. Organizational implications: as Behemoth is Meta's "flagship" AI model, the delay affects the credibility of Meta's broader "AI-First" positioning after Zuckerberg's public commitments. Reports suggest internal discussions about AI product group operational structure and leadership are surfacing alongside the technical challenges. Industry pattern: Llama 4 Behemoth joins a growing list of delayed frontier models (including early delays of GPT-5 and Gemini Ultra 2), suggesting that scaling laws may be hitting practical limits where proportional capability improvements require disproportionate compute investments — a structural challenge for the "bigger is better" frontier AI development paradigm.


