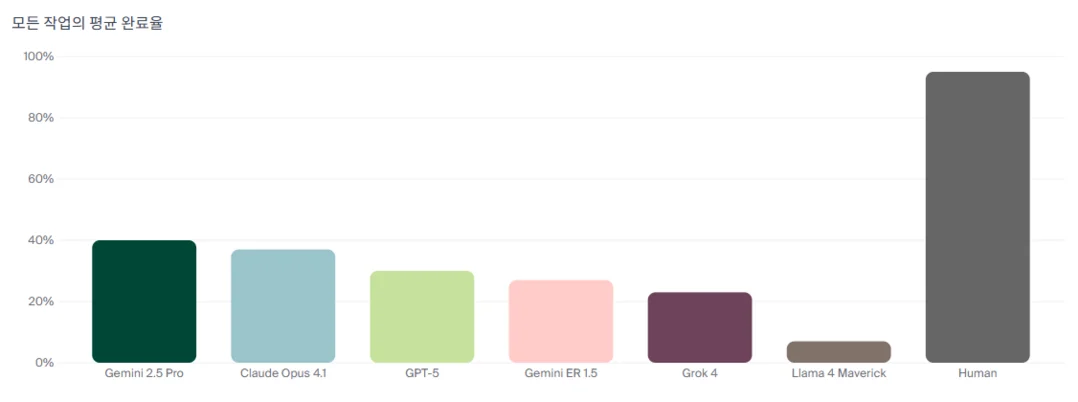
"AI understands vast papers but still cannot pass a single stick of butter." Andon Labs "Butter-Bench" experiment is the world first research measuring how much "practical intelligence" large language models (LLMs) can exercise in the actual physical world. Results were stark: human average score 95%; state-of-the-art LLMs including GPT-5, Gemini 2.5 Pro, and Claude Opus scored only 40% -- a deep intelligence gap still exists between AI "linguistic genius" and "reality sense." October 21, 2025: Sweden-based Andon Labs released "Butter-Bench" -- not merely a technical experiment but the first answer to the fundamental question: "Can AI understand the human physical world and act socially?" Tested models: GPT-5 (OpenAI), Claude Opus 4.1 (Anthropic), Gemini 2.5 Pro/ER 1.5 (Google DeepMind), Grok 4 (X), Llama 4 Maverick (Meta). The butter benchmark: the test measured whether AI can understand what to do in the situation "can you pass the butter?" at a dinner table -- not as a literal task for a disembodied AI but as a test of understanding social context, physical world constraints, and practical task decomposition. Humans naturally understand: identify where the butter is, pick it up, pass it to the person who asked. AI must understand: the social situation (dinner table context), the physical constraint (butter is a physical object that must be physically moved), the action sequence (find, grasp, move, release), and the social appropriateness (respond in a way that acknowledges the request). Why AI fails the butter test: LLMs excel at language tasks but lack "embodied understanding" -- they have never experienced picking up an object, feeling its weight, or navigating the physical and social constraints of sharing food at a table. Physical AI (robots) scores higher than text-only LLMs but still far below humans on tasks requiring integrated physical-social intelligence. The benchmark significance: while AI benchmarks typically measure abstract reasoning (math, coding, logic), Butter-Bench measures the type of common-sense practical intelligence that humans use constantly in daily life -- the 40% vs 95% gap reveals that AI capability gaps in practical domains are much larger than capability gaps in academic domains.
Why AI Can't Pass the 'Butter'
The significance of Andon Labs' 'Butter-Bench' experiment. 'AI understands vast papers but still can't pass a piece of butter.' Andon Labs revealed results that reveal the limits of AI embodiment.
Source: META-X metax.kr
The Meaning of Andon Labs "Butter-Bench" Experiment
ⓒ META-X metax.kr
All rights reserved.
Free to share with attribution.
All rights reserved.
Free to share with attribution.


