




에이전트의 메모리·협업 효율을 극대화하고 환경 적응력을 높이는 다양한 오픈소스 프레임워크 공개
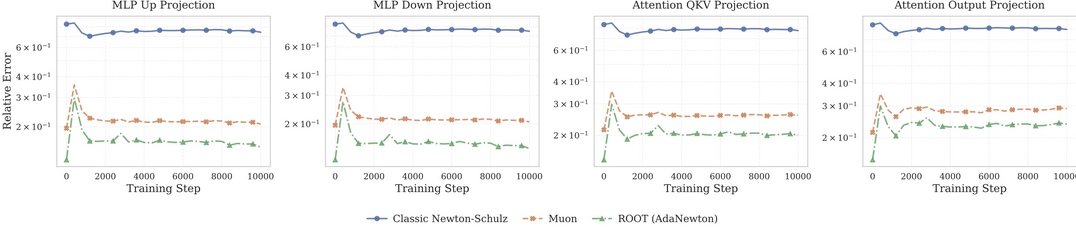
ROOT: Robust Orthogonalized Optimizer for Neural Network Training
https://arxiv.org/abs/2511.20626
[메타X(MetaX)] 대규모 언어 모델 훈련 시 발생하는 알고리즘의 정밀도 문제와 훈련 불안정성을 해결하기 위해, 이중 강건성 메커니즘을 갖춘 새로운 최적화 도구인 ROOT를 제안했다. 이 기법은 행렬 크기에 맞춘 적응형 뉴턴 반복법을 통해 직교화 정밀도를 일관되게 유지하고, 근접 최적화 방식을 도입하여 이상치 노이즈를 효과적으로 억제한다. 실험 결과, ROOT는 기존 Muon이나 Adam 기반 최적화 도구보다 노이즈가 많거나 비볼록한 환경에서도 더 빠른 수렴 속도와 뛰어난 최종 성능을 달성하여 대규모 모델 훈련의 안정성을 크게 향상시켰다.
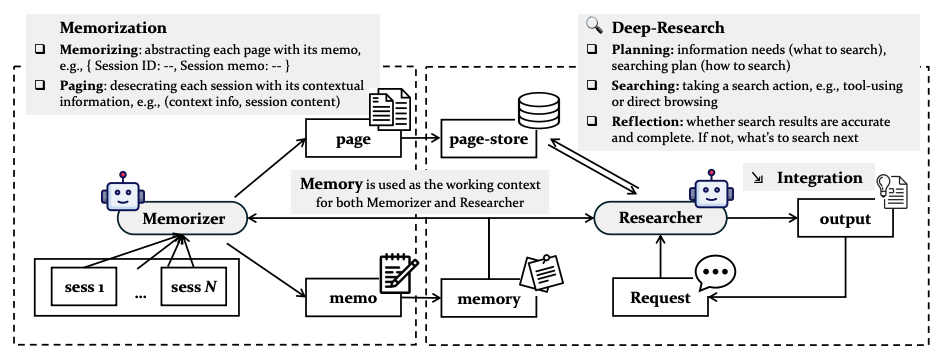
General Agentic Memory Via Deep Research
https://arxiv.org/abs/2511.18423
기존 정적 메모리 방식의 정보 손실 문제를 해결하기 위해, 런타임에 필요한 컨텍스트를 최적화하여 생성하는 '적시(JIT) 컴파일' 원칙 기반의 일반 에이전트 메모리(GAM) 프레임워크를 제안했다. GAM은 핵심 정보만 가볍게 기억하고 전체 역사는 페이지 저장소에 보관하는 'Memorizer'와, 필요에 따라 저장소에서 정보를 검색 및 통합하는 'Researcher'로 구성되어 에이전트의 능력을 극대화한다. 강화 학습을 통한 최적화를 지원하는 이 구조는 다양한 메모리 기반 작업 시나리오에서 기존 시스템 대비 상당한 성능 향상을 입증했다.
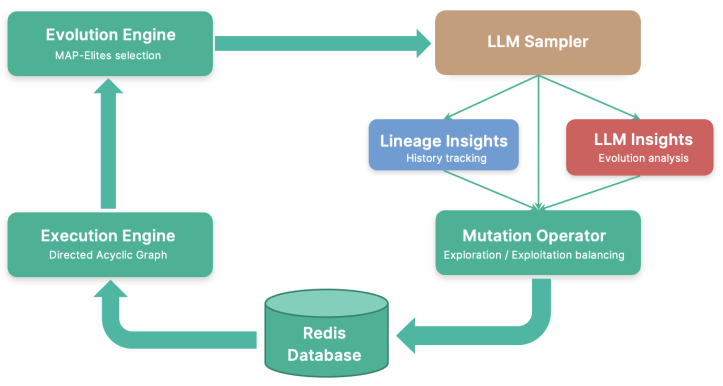
GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms
https://arxiv.org/abs/2511.17592
최근 주목받는 LLM 기반 진화 연산 연구들의 구체적인 구현 세부 사항이 부족하여 재현이 어려운 문제를 해결하고자, 확장 가능한 오픈 소스 프레임워크인 GigaEvo를 공개했다. 이 프레임워크는 MAP-Elites 알고리즘, 비동기 파이프라인, LLM 주도 돌연변이 연산 등 핵심 구성 요소를 모듈화하여 제공하며, AlphaEvolve 논문의 난이도 높은 최적화 문제들을 통해 성능과 재현성을 검증했다. 연구자들은 이 도구를 통해 하이브리드 LLM-진화 접근법을 쉽게 실험하고 프로토타이핑할 수 있다.

GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization
https://arxiv.org/abs/2511.15705
이미지 조작에 치중된 기존 시각적 추론 연구의 한계를 넘어, 웹 검색과 정밀한 시각적 근거가 필요한 지리적 위치 추정(Geolocalization) 작업을 수행하는 에이전트 모델 GeoVista와 이를 평가할 GeoBench를 제안했다. GeoVista는 이미지 확대 및 웹 검색 도구를 추론 과정에 통합하고, 지도 학습과 계층적 보상 기반의 강화 학습을 통해 훈련되어 추론 능력을 극대화했다. 실험 결과, GeoVista는 타 오픈소스 에이전트 모델을 크게 능가하며 Gemini-2.5-flash나 GPT-5와 같은 폐쇄형 모델과 대등한 성능을 달성했다.
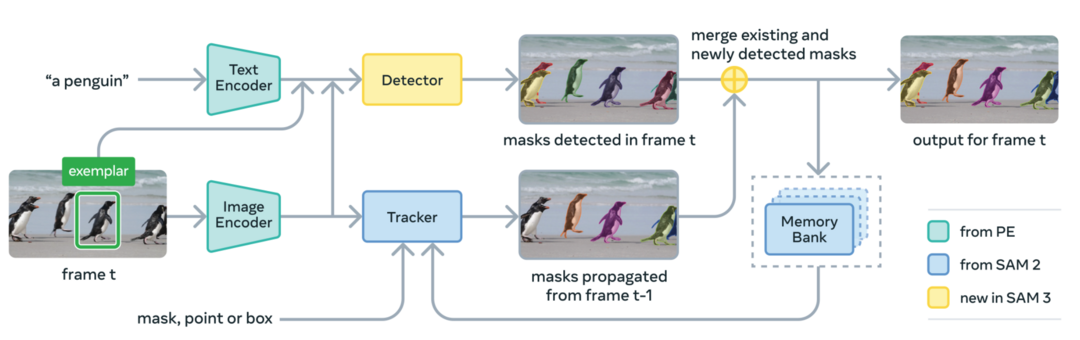
SAM 3: Segment Anything with Concepts
https://arxiv.org/abs/2511.16719
텍스트 문구나 이미지 예시와 같은 '개념 프롬프트'를 기반으로 이미지와 비디오 내 객체를 검출, 분할, 추적할 수 있는 통합 모델 SAM 3를 제안했다. 이를 위해 400만 개의 고유 개념 라벨을 포함한 대규모 데이터셋을 구축하고, 이미지 검출기와 메모리 기반 비디오 추적기가 백본을 공유하는 구조를 설계하여 인식과 위치 정밀도를 높였다. SAM 3는 기존 시스템 대비 프롬프트 기반 개념 분할(PCS) 정확도를 두 배로 향상시켰으며, 관련 벤치마크와 함께 오픈 소스로 공개되었다.
OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe
https://arxiv.org/abs/2511.16334
멀티모달 추론 연구의 투명성과 재현성을 높이기 위해, 지도 학습(SFT)과 강화 학습(RL)을 아우르는 2단계 훈련 프레임워크인 OpenMMReasoner를 제안했다. 엄격한 단계별 검증을 거친 87만 개의 SFT 데이터셋과 7만 개의 RL 데이터셋을 구축하여 모델의 추론 능력을 체계적으로 강화하고 안정화했다. 이 방법론은 Qwen2.5-VL-7B-Instruct 대비 11.6%의 성능 향상을 기록했으며, 모든 코드와 데이터 파이프라인이 공개되어 후속 연구의 기반을 마련했다.

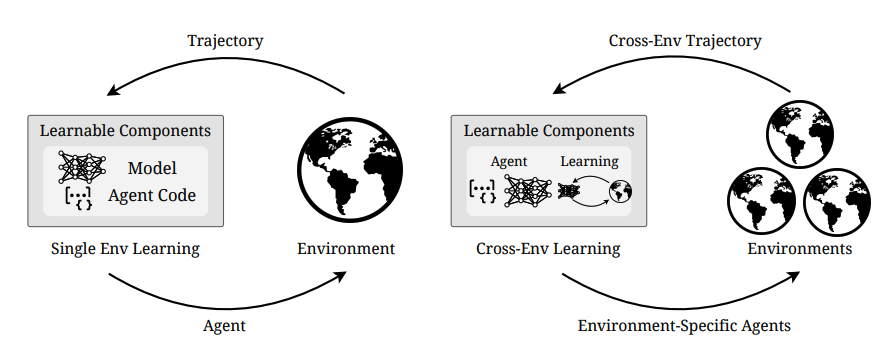
AutoEnv: Automated Environments for Measuring Cross-Environment Agent Learning
https://arxiv.org/abs/2511.19304
단일 도메인에 국한된 기존 에이전트 평가의 한계를 넘어 다양한 환경에 적응하는 능력을 측정하기 위해, 이질적인 환경을 저비용으로 자동 생성하는 AutoEnv 프레임워크와 36개 환경으로 구성된 AutoEnv-36 데이터셋을 제안했다. 에이전트 학습 과정을 선택, 최적화, 평가 단계로 공식화하여 분석한 결과, 고정된 학습 방법은 환경이 다양해질수록 성능이 저하되며 환경에 맞게 학습법을 적응시키는 것이 중요함을 밝혀냈다. 이는 에이전트의 교차 환경 일반화 능력을 연구하기 위한 새로운 테스트베드로서의 가치를 보여준다.
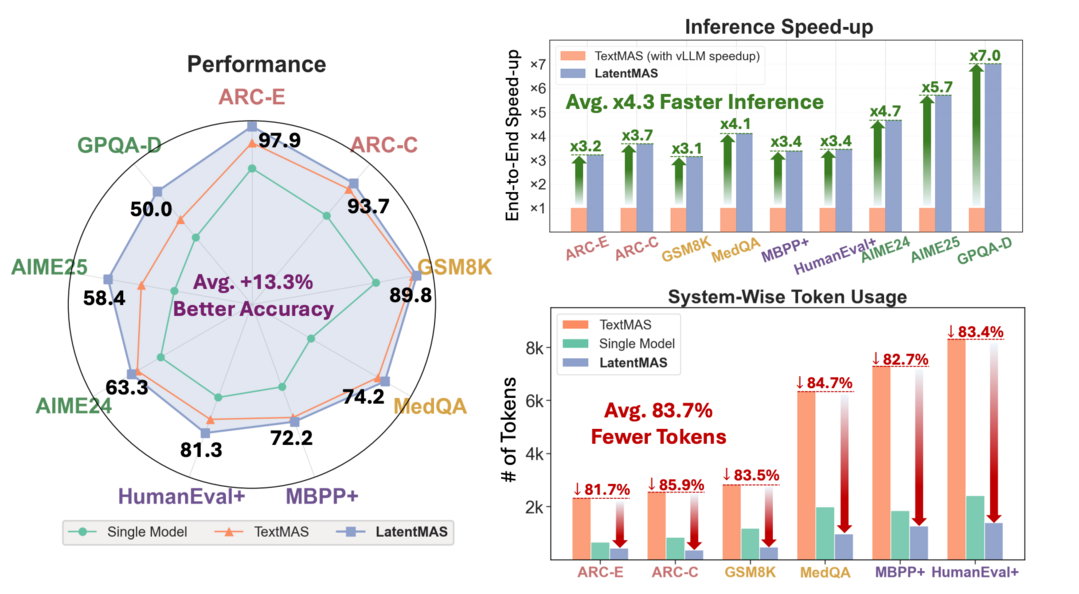
Latent Collaboration in Multi-Agent Systems
https://arxiv.org/abs/2511.20639
기존 텍스트 기반 다중 에이전트 시스템의 비효율성을 개선하기 위해, 에이전트들이 텍스트가 아닌 연속적인 잠재 공간(Latent Space)에서 직접 협업하는 훈련 불필요 프레임워크인 LatentMAS를 제안했다. 이 시스템은 공유 잠재 작업 메모리를 통해 에이전트 간 정보 손실 없는 교환을 가능하게 하며, 이론적으로 더 높은 표현력과 낮은 복잡성을 가진다. 실험 결과, LatentMAS는 기존 방식 대비 최대 14.6% 높은 정확도와 4배 이상 빠른 추론 속도를 달성하고 토큰 사용량을 대폭 절감하여 시스템 수준의 추론 품질과 효율성을 동시에 입증했다.
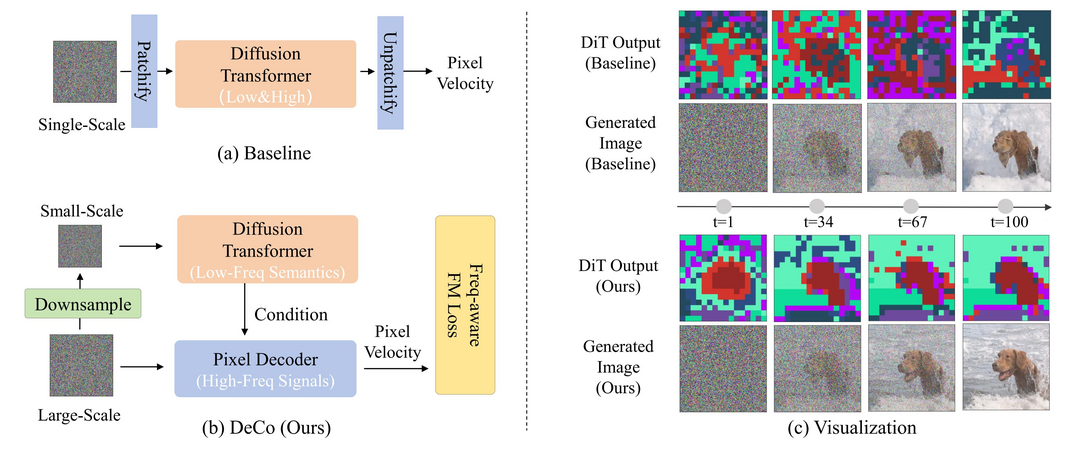
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
https://arxiv.org/abs/2511.19365
기존 픽셀 디퓨전 모델의 느린 속도와 비효율성을 개선하기 위해, 고주파와 저주파 신호 생성을 분리하는 'DeCo' 프레임워크를 제안했다. 이 방식은 가벼운 픽셀 디코더가 고주파 세부 묘사를 담당하고 확산 트랜스포머(DiT)는 저주파의 의미적 정보에 집중하도록 설계되었으며, 주파수 인지 흐름 매칭 손실 함수를 도입하여 성능을 최적화했다. 실험 결과 DeCo는 ImageNet에서 뛰어난 FID 점수를 기록하며 잠재 디퓨전 방식과의 격차를 좁혔고, 텍스트-이미지 생성에서도 우수한 평가를 받았다.
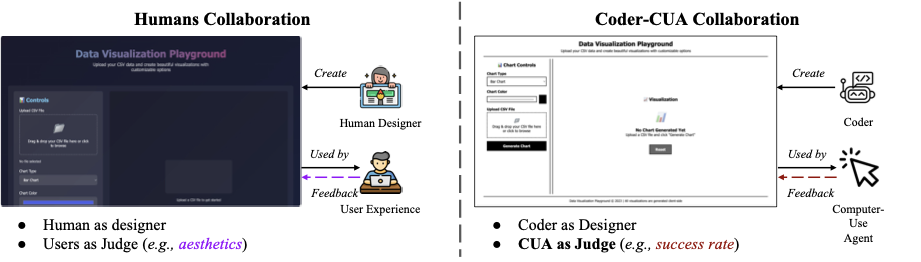
Computer-Use Agents as Judges for Generative User Interface
https://arxiv.org/abs/2511.15567
인간 중심의 그래픽 사용자 인터페이스(GUI)가 컴퓨터 사용 에이전트(CUA)에게 비효율적인 문제를 해결하고자, CUA를 심사위원으로 활용하여 자동 GUI 설계를 돕는 프레임워크를 제안했다. 이를 위해 다양한 도메인의 52개 애플리케이션을 포함한 AUI-Gym 벤치마크를 구축하고, 코더 모델이 웹사이트를 설계하면 CUA가 작업 해결 가능성을 기준으로 평가하고 피드백을 제공하는 협업 구조를 고안했다. 이 연구는 시각적 미학보다는 에이전트의 작업 효율성과 신뢰성을 최우선으로 하는 새로운 인터페이스 디자인 패러다임을 제시한다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]